

Ground Truth Is the Spec
Why generic LLM-as-judge metrics aren't measuring what your product is for — and what to do about it.


There’s a particular way AI products fail that I keep seeing.
The model didn’t regress.
The prompt didn’t break.
The deployment is stable.
The evaluation dashboard reads green across every metric the team is tracking.
But the retention numbers don’t track.
I’ve been in enough rooms with AI builders now to recognize the shape of it.
It isn’t a one-team problem.
It’s a pattern that scales with how mature AI products are getting, and most teams I talk to are walking into it from the same direction — chasing scalable measurement and quietly losing the signal in the process.
The shape, stated cleanly:
Your evaluation scores and your user experience are drifting apart, and your current setup cannot detect the drift.
This edition is about why that happens, what the research now says about it, and what the discipline of closing the gap actually looks like.
In the next edition I’ll address the question that should immediately follow — “what do I do when I don’t have users yet?” — which is a separate problem that deserves its own treatment.
The comfortable answer
For most of the last two years, the industry converged on a comfortable answer to the eval problem.
You build your AI feature.
You write a rubric (or use a generic one off-the-shelf — relevance, accuracy, comprehensiveness, helpfulness, tone)
You hand the rubric to an LLM judge.
The judge produces scores.
The scores go on a dashboard.
It scales. It runs nightly. It costs cents per evaluation. It looks like measurement.
The trap is that it isn’t measurement.
It’s a confident vibe-check by a system with predictable, documented biases — and on the kinds of products that matter most (high-value customers, agents with tools, niche platforms, regulated domains), those biases dominate the signal.
The documented biases
The published evidence is no longer subtle.
A 2024 study analyzed position bias across more than 150,000 evaluation instances and 22 tasks (Shi et al., 2024). The bias is worst exactly when the two candidate answers are close in quality — the close calls that drive ranking decisions. Length bias is documented and traces back to RLHF preference data: longer answers are systematically preferred even when content is matched (Saito et al., 2023). Self-preference is empirically demonstrated: LLM judges score their own generations measurably higher than humans rate them, and the bias correlates linearly with how well the judge can recognize its own writing (Panickssery et al., NeurIPS 2024).
Then there’s the finding that should keep anyone awake who depends on a general rubric.
The 2024 SOS-BENCH meta-benchmark — the largest study of its kind, accepted to ICLR 2025 — concluded that “LLM-judge preferences do not correlate with concrete measures of safety, world knowledge, and instruction following.” They rate stylish answers above correct ones. They are critical of unconventional formatting and forgiving of factual errors.
And the comparison that puts numbers on the gap, from Snorkel AI’s published enterprise eval work: off-the-shelf LLM judges agreed with subject-matter experts only 70–75% of the time on real enterprise tasks. After calibration against a small human-labeled set, agreement climbed to 88–90% — what the researchers called “enough to trust.”
Twenty percentage points sit between the default setup and a trustworthy one.
The default isn’t a starting point. It’s a measurement bug.
The conversation I keep having
Every few weeks I find myself in a version of the same conversation.
Someone on an AI product team — usually trying to do the right thing — pushes back on the idea of building a hand-annotated eval set. The argument is consistent enough that it’s worth restating fairly:
“Hand-curated ground truth doesn’t scale. We can’t keep up with annotation for every new customer, every new agent, every prompt change. LLM-as-judge with general rubrics — relevance, accuracy, helpfulness, comprehensiveness — does scale. It runs nightly. It costs cents. It gives us coverage. We should default to that, and only reach for human annotation in edge cases.”
I want to take this argument seriously, because there’s a real thing buried inside it.
Generic LLM-as-judge is useful.
For first-pass coverage scoring, for triage across millions of traces, for preference judgments where the cost of being wrong is low — it has a legitimate role.
The industry’s convergence on it isn’t dumb.
There’s a real coverage problem in modern AI eval, and hand-annotating every trace is genuinely prohibitive.
But the argument as stated collapses two things that need to stay separate.
Coverage and ground truth are not the same thing.
A scoring system that runs cheaply across millions of traces is a coverage tool.
A scoring system that tells you whether your product is good for your users is a ground-truth tool.
Generic LLM judges, as the research above demonstrates repeatedly, are the first. They are not the second.
The right question isn’t “human annotation vs LLM judge.”
The right question is: do you have a calibrated mapping from one to the other?
If you don’t, your nightly judge scores are measuring the judge’s preferences, not your product’s quality. The scale is real. The signal isn’t.
This is the part that almost every team I talk to has not yet internalized — and it’s the conflict at the center of this whole conversation.
The deeper trap
You could read all of the above and decide the answer is to use a better LLM judge.
It’s not the answer.
There’s a 2024 UIST paper from Shreya Shankar and collaborators that, taken seriously, changes the whole shape of how AI products should be evaluated. The central finding (Shankar et al., UIST 2024):
“Users need criteria to grade outputs, but grading outputs helps users define criteria.”
This phenomenon has a name now — criteria drift. It says something epistemologically uncomfortable: you cannot fully write the evaluation rubric upfront. Some of what matters about your product can only be discovered by looking at outputs.
Sit with that.
Every post arguing that evaluation rubrics are the new specification implicitly assumes you can decide quality first and measure against it. The research says the opposite. The specification is emergent. The act of looking at real outputs is what teaches you what your product is actually trying to be.
This is why the better-LLM-judge fix doesn’t work. It isn’t that the judge is bad. It’s that the rubric the judge is enforcing was hallucinated — written before anyone in the room knew enough about the product to write it.
There’s no way around this. There’s only a way through.
What the discipline looks like
The principle without the practice is the kind of post that adds anxiety rather than reducing it. So here’s the practice — compressed.
The composite recipe I keep seeing in teams that actually build reliable AI products — and that the published literature converges on — has seven moves.
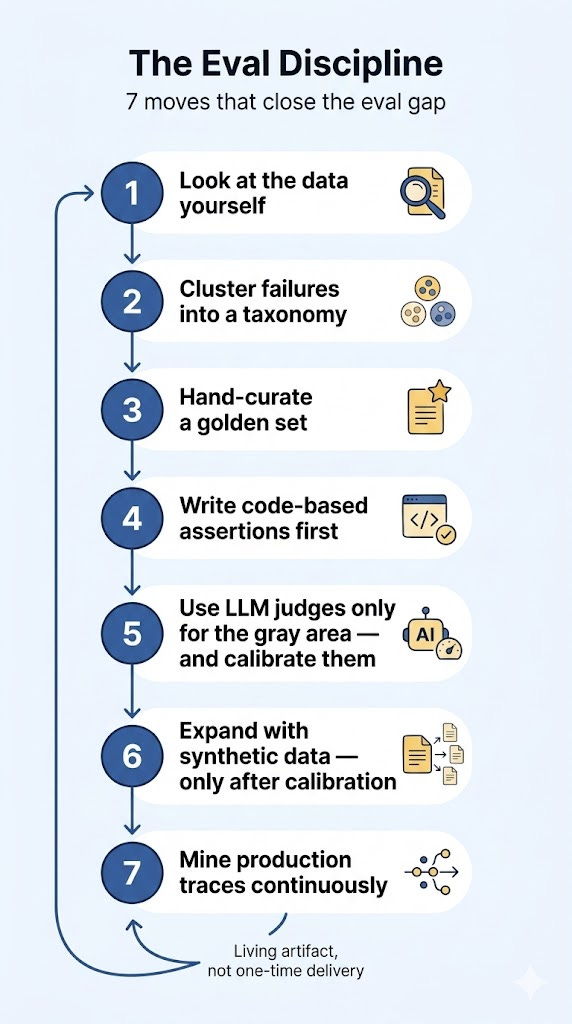
1. Look at the data yourself
Thirty to fifty real outputs.
No tooling, no LLM judge.
Open a spreadsheet, write a one-line note next to each one describing what’s good or bad about it.
This is the irreducible core.
Everything below collapses without it.
2. Cluster the failures into a taxonomy
Group the notes.
What are the 3–5 categories of failure that keep recurring? Quantify them.
In Hamel Husain’s Field Guide to Rapidly Improving AI Products, a leasing AI team that did exactly this discovered three failure categories accounting for 60% of all production failures. Date-handling success went from 33% to 95% after focused fixes — work they could not have prioritized without first seeing the distribution.
3. Hand-curate a golden set
100–500 examples, each with an expected output.
One accountable person owns it.
For high-stakes scenarios, co-author with the customer.
4. Write code-based assertions first
Anything deterministic gets a deterministic check:
Schema validation
Tool-call correctness
Refusal detection
Date format conformance
These run on every commit.
Cheap, fast, exactly right.
5. Use LLM judges only for the subjective gray area
And — this is the move most teams skip — calibrate the judge against the golden set.
Measure judge-vs-human agreement.
Iterate the judge prompt until agreement clears a defined threshold (Snorkel’s empirical bar was around 88–90%).
Only then can you trust the judge to score at scale.
6. Expand with synthetic data — only after calibration
Use the calibrated judge as the filter.
Use real failure modes as the generation seed.
Never trust raw synthetic outputs as gold labels.
7. Mine production traces continuously
Every new failure mode that surfaces in production updates the taxonomy and propagates back to the golden set.
The eval suite becomes a living artifact, not a one-time delivery.
What the work actually is — and who does it
The recipe is straightforward enough. The reason it doesn’t get implemented isn’t ignorance.
It’s the activity at step 1 — looking at the data yourself — which almost every team wants to outsource and almost no team should.
Let me be specific about what this activity actually costs.
In a working AI product team, “looking at the data” amounts to one person spending roughly one hour per week reading 5–10 failed outputs, writing a one-line note about what went wrong, and adding it to the failure taxonomy.
One hour.
Per week.
By someone who understands what the product is trying to do for the user.
Not training-data annotation.
Not labeling at the scale of supervised learning.

The work here is judgment, encoded as examples — the gradual, accumulating record of what your product means by “good.”
When the resistance to this work surfaces, the first version of it is “it doesn’t scale.” That’s the argument I addressed above.
Annotation in modern AI products doesn’t scale linearly with users — it scales to saturation. After 20–50 traces per category, new failures stop revealing new categories.
The taxonomy is the artifact that scales.
The calibrated judge is the artifact that scales.
The 100-example golden set scales by being durable, not by being large.
The activity is concentrated, recurring, and small.
But there’s a second version of the resistance that surfaces, and it’s the more honest one:
“Fine — but who in the team is supposed to actually do that hour?”
The answer is uncomfortable for almost every role I work alongside, including my own.
Not the engineer or the applied scientist, who has the deepest technical context but rarely the deepest customer context.
Not a contracted annotation vendor, who has neither.
Not “the AI team” as a collective, because diffuse ownership of judgment converges on no judgment at all.
The work has to be done by someone who:
Has persistent access to what the customer is actually trying to do,
Can make a binary call on whether an output is good enough for that customer’s job-to-be-done,
And is accountable for the answer.
In every team I’ve watched do this well, that intersection lives with the people closest to the product’s user — typically the product manager, sometimes a forward-deployed or customer-success engineer, sometimes the customer themselves. Not because engineers and scientists can’t read traces — we should, and we do — but the encoding of customer expectations into expected outputs is product judgment, not technical judgment.
This is also why “let’s hire a labeling team” almost always disappoints.
Labelers don’t have persistent customer context.
They produce confident, internally consistent annotations against the wrong rubric.
Hamel Husain calls the right pattern the benevolent dictator — a single accountable person, deeply embedded in the product’s domain, who owns the quality call. Committees of part-time annotators converge on the wrong answer. So do outsourced labeling teams. So does the “whoever has bandwidth this sprint” model.
The work isn’t optional and it isn’t transferable.
It’s the work.
The compounding core
Most discussions of evals frame the work as a tax — necessary overhead on top of building.
I think that’s backwards.
The annotation work is the only activity in the eval pipeline that actually encodes your understanding of your product.
The dashboards measure.
The judges score.
The vendor tools orchestrate.
The only piece that contains domain knowledge — the only piece that knows whether your product is any good for the people who use it — is the human-judged examples at the center of the loop.
Everything else is scaffolding around that core.
If you read one thing from this edition and act on it, let it be this:
The eval discipline isn’t a quality-control function bolted onto building.
It’s the slow accumulation of judgment about your product,
in a form that survives model swaps, prompt changes, and team turnover.
That’s the asset.
The next question
There’s an obvious objection to everything above. “This assumes I already have production traffic. What if I’m pre-launch — building V0, in a design-partner stage, working on an internal feature, gating a regulated rollout — and I have no users to learn from?”
That’s the harder problem, and it deserves its own edition.
In the next one I’ll lay out the playbook for greenfield evals — what to do when you have zero traces, how to manufacture realistic signal from spec, personas, design partners, and expert simulation, and how every artifact you build in the cold-start phase hands off cleanly to the post-launch discipline above.
It’s the most underwritten part of AI product development right now. I’ll cover it next.
When you look at the last 20 outputs your AI system produced, how many of them would you say your current evaluation actually scores correctly?
Who in your team would you trust to make that call?
I’d love to hear your thoughts about these.
Until next time — keep the signal, drop the noise.
— Tezan